Reservoir computing, which maps input data onto a high-dimensional computational space while keeping some artificial neural network (ANN) parameters fixed and updating others, is a promising computational framework based on recurrent neural networks (RNNs). In addition to reducing the amount of data required to adequately train machine learning algorithms, this framework may also help enhance their performance.
RNNs basically process sequential data and make accurate predictions by utilizing recurrent connections between their various processing units. While RNNs have been found to perform well on various undertakings, advancing their exhibition by distinguishing boundaries that are generally applicable to the errand they will handle can be testing and tedious.
An alternative approach to designing and programming RNN-based reservoir computers was recently presented by University of Pennsylvania researchers Jason Kim and Dani S. Bassett, who were inspired by the way programming languages function on computer hardware. This methodology, distributed in Nature Machine Knowledge, can distinguish the suitable boundaries for a given organization, writing computer programs for its calculations to streamline its presentation on track issues.
“The success of recurrent neural networks (RNNs) in modeling brain dynamics and learning complex computations inspired us. Based on that motivation, we posed a simple question: what if we could program RNNs the same way we program computers? Prior research in control theory, dynamical systems, and physics had convinced us that it was not an unrealistic dream.”
Jason Kim and Dani S. Bassett, two researchers at University of Pennsylvania.
Kim told Tech Xplore, “We have always been interested in how the brain represents and processes information, whether it’s calculating a tip or simulating multiple moves in a game of chess.” We were inspired by the success of recurrent neural networks (RNNs) in learning complex computations and modeling brain dynamics. We asked a straightforward question based on that inspiration: What if we were able to program RNNs similarly to computers? It was not an impossible dream, as previous research in control theory, dynamical systems, and physics demonstrated.”
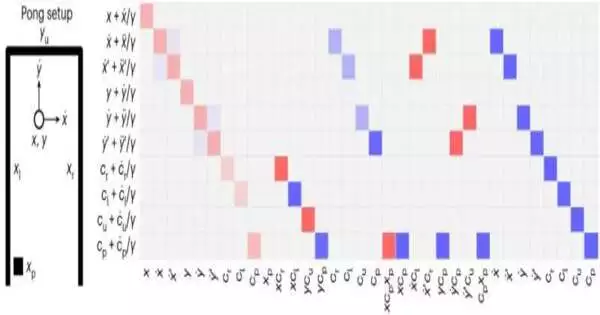
The brain machine code presented by Kim and Bassett was accomplished by decompiling the inside portrayals and elements of RNNs to direct their examination of information. Their methodology looks like the most common way of incorporating a calculation on PC equipment, which involves enumerating the areas and timings at which individual semiconductors should be turned here and there.
Kim explained, “In an RNN, these operations are specified simultaneously in the weights distributed across the network, and the neurons simultaneously run the operations and store the memory.” To extract the algorithm that is currently being run on an existing set of weights and to define the set of operations (connection weights) that will run a desired algorithm (such as solving an equation or simulating a video game), we use mathematics. Our method has two distinct advantages: it doesn’t need any data or sampling, and it defines not just one connectivity but a space of patterns of connectivity that run the desired algorithm.
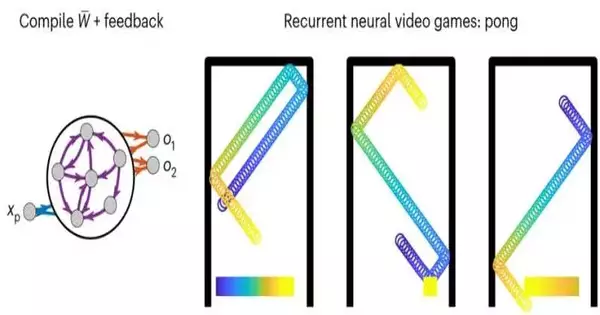
playing a pong game that a recurrent neural network is simulating. Credit: Nature Machine Intelligence (2023). DOI: 10.1038/s42256-023-00668-8
The researchers used their framework to create RNNs for a variety of applications, including virtual machines, logic gates, and an AI-powered ping pong video game, demonstrating the advantages of their approach. All of these algorithms performed exceptionally well, necessitating no trial-and-error parameter adjustments.
“One outstanding commitment of our work is a change in perspective in the way we comprehend and concentrate on RNNs from information handling devices to completely fledged PCs,” Kim said. “As a result of this shift, we are now able to design RNNs that can carry out tasks without the use of backpropagation or training data and can examine a trained RNN to determine the issue it is addressing. For all intents and purposes, we can introduce our organizations with a speculation-driven calculation instead of irregular loads or a pre-prepared RNN, and we can straightforwardly separate the gained model from the RNN.”
This group’s neural machine code and programming framework could soon be used by other groups to create RNNs with higher performance and simpler parameter adjustments. It is Kim and Bassett’s long-term goal to use their framework to develop fully functional software for neuromorphic hardware. They also intend to develop a method for extracting algorithms learned by trained reservoir computers in their subsequent research.
Kim stated, “While neural networks are exceptional at processing complex and high-dimensional data, these networks tend to cost a lot of energy to run, and it is extremely challenging to understand what they have learned.” Our work gives a steppingstone to straightforwardly decompiling and making an interpretation of the prepared loads into an express calculation that can be run substantially more effectively without a requirement for the RNN and further examined for logical comprehension and execution.”
Bassett’s examination group at the College of Pennsylvania is likewise dealing with utilizing AI, especially RNNs, to repeat human mental cycles and capacities. Their efforts in this field of study may be aided by the neural machine code that they recently developed.
“A second thrilling exploration heading is to plan RNNs to perform undertakings normal for human mental capability,” Dani S. Bassett, the Teacher managing the review, added. “We envision designing RNNs that engage in attention, proprioception, and curiosity by employing theories, models, or data-derived definitions of cognitive processes. We are eager to comprehend the connectivity profiles that support such distinct cognitive processes in this manner.”
More information: Jason Z. Kim et al, A neural machine code and programming framework for the reservoir computer, Nature Machine Intelligence (2023). DOI: 10.1038/s42256-023-00668-8




