Automated flying vehicles (UAVs), generally known as robots, have previously demonstrated that they are priceless for handling a great many certifiable issues. For example, they can help people with conveyances, natural observation, film production, and search and salvage missions.
While the exhibition of UAVs worked on significantly over the course of the last 10 years or something like that, large numbers of them actually have somewhat short battery durations; consequently, they can run out of force and quit working prior to finishing a mission. Numerous new examinations in the field of mechanical technology have, in this manner, pointed toward further developing these frameworks’ battery duration while additionally creating computational strategies that permit them to handle missions and plan their courses as proficiently as could really be expected.
Scientists at the Specialized College of Munich (TUM) and the College of California Berkeley (UC Berkeley) have been attempting to devise improved answers for handling the usually fundamental examination issue, which is known as inclusion way arranging (CPP). In a new paper pre-distributed on arXiv, they presented another support learning-based device that streamlines the directions of UAVs all through a whole mission, including visits to charging stations when their battery is running short.
“We wanted to extend the CPP problem in our new paper by allowing the agent to recharge, so that the UAVs considered in this model could cover a much larger space. In addition, we needed to ensure that the agent did not breach safety limits, which is an obvious necessity in a real-world scenario.”
Alberto Sangiovanni-Vincentelli explained, Researchers at Technical University of Munich (TUM)
“The foundations of this exploration date back to 2016, when we began our examination of “sunlight-based controlled, long-perseverance UAVs,” Marco Caccamo, one of the analysts who did the review, told Tech Xplore.
“Years after the beginning of this exploration, obviously CPP is a vital part of empowering UAV sending to a few application spaces like computerized farming, search and salvage missions, observation, and numerous others. It is a perplexing issue to settle as needs might arise, including impact evasion, camera field of view, and battery duration. This prompted us to examine support for advancing as a likely answer for integrating this large number of variables.”
In their past works, Caccamo and his partners attempted to handle less complex forms of the CPP issue by utilizing support learning. In particular, they considered a situation in which a UAV had battery requirements and was required to handle a mission within a restricted period of time (i.e., before its battery ran out).
In this situation, the specialists utilized support to figure out how to permit the UAV to finish a very remarkable mission or travel through however much space as could be expected with a solitary battery charge. As such, the robot couldn’t interfere with the mission to re-energize its battery, hence re-beginning from where it halted previously.
“Also, the specialist needed to become familiar with the wellbeing imperatives, i.e., crash evasion and battery limits, which yielded safe directions more often than not, however few out of every odd time,” Alberto Sangiovanni-Vincentelli made sense of. “In our new paper, we needed to broaden the CPP issue by permitting the specialist to re-energize with the goal that the UAVs considered in this model could cover a lot more space. Moreover, we needed to ensure that the specialist didn’t disregard security limitations, an undeniable prerequisite in a certifiable situation. “
A vital benefit of support learning approaches is that they will quite often sum up well across various cases and circumstances. This means that in the wake of preparing with support learning strategies, models can frequently handle issues and situations that they didn’t experience previously.
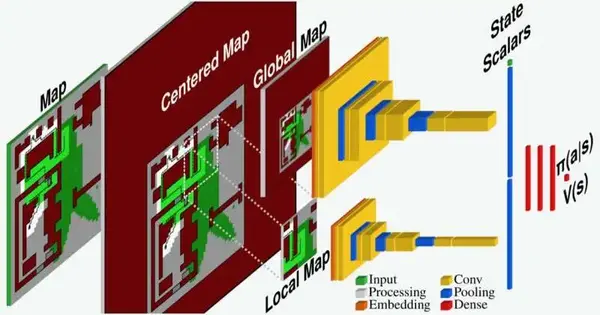
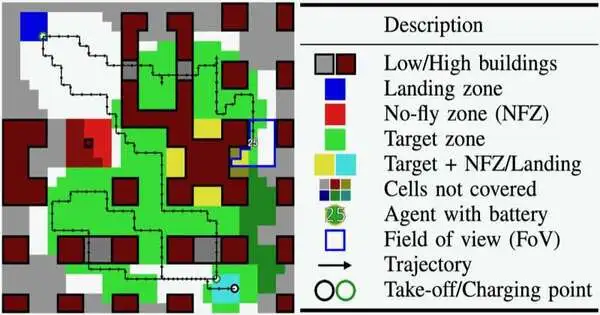
How the support learning specialist notices and cycles the climate It notices a guide portrayal of the issue, which it then bases on its situation. It then, at that point, packs the whole focused map into a worldwide guide with a decreased goal and a full-goal nearby guide, which shows just the quick area of the specialist. The specialist then, at that point, processes these two guides through various brain network layers until the specialist yields an activity choice. Credit: Theile et al.
This capacity to sum up extraordinarily relies on how an issue is introduced to the model. In particular, the profound learning model ought to have the option to check out the current circumstances in an organized manner, for example, as a guide.
To handle the new CPP situation considered in their paper, Caccamo, Sangiovanni-Vincentelli, and their partners fostered another support learning-based model. This model basically notices and cycles the climate in which a UAV is moving, which is addressed as a guide, and revolves it around its situation.
In this manner, the model packs the whole ‘focused map’ into a worldwide guide with a lower goal and a full-goal nearby guide showing just the robot’s prompt area. These two guides are then investigated to upgrade directions for the UAV and choose its future activities.
“Through our interesting guide handling pipeline, the specialist can remove the data it requires to take care of the inclusion issue in concealed situations,” Mirco Theile said. “Moreover, to ensure that the specialist doesn’t disregard the security limitations, we characterized a security model that figures out which of the potential activities are protected and which are not. Through an activity concealing methodology, we influence this security model by characterizing a bunch of safe activities in each circumstance the specialist experiences and allowing the specialist to pick the best activity among the protected ones.”
The specialists assessed their new streamlining device in a progression of starting tests and found that it essentially beat a standard direction-arranging strategy. Remarkably, their model summed up well across various objective zones and known maps and could likewise handle a few situations with inconspicuous guides.
“The CPP issue with re-energize is essentially more testing than the one without re-energize, as it stretches out throughout a significantly longer time skyline,” Theile said. “The specialist needs to go with long-haul arranging choices, for example, concluding which target zones it ought to cover now and which ones it can cover while getting back to re-energize. We show that a specialist with map-based perceptions, security model-based activity concealing, and extra factors, for example, markdown factor booking and position history, can settle major areas of strength for on-skyline choices.”
The new support learning-based approach presented by this group of researchers ensures the wellbeing of a UAV during activity, as it just permits the specialist to choose safe directions and activities. Simultaneously, it could work on the capacity of UAVs to actually finish missions, improving their directions to focal points, target areas, and charging stations when their battery is low.
This new review could rouse the advancement of comparative strategies to handle CPP-related issues. The group’s code and programming are openly accessible on GitHub; in this manner, different groups overall could before long execute and test it on their UAVs.
“This paper and our past work tackled the CPP issue in a discrete matrix world,” Theile added. “For future work, to draw nearer to certifiable applications, we will examine how to bring the significant components—map-based perceptions and security activity—into the constant world. Tackling the issue in consistent space will empower its sending in true missions, for example, brilliant cultivating or natural observing, which we trust can have an extraordinary effect.”
More information: Mirco Theile et al, Learning to Recharge: UAV Coverage Path Planning through Deep Reinforcement Learning, arXiv (2023). DOI: 10.48550/arxiv.2309.03157
Journal information: arXiv




