
Preparing robots to finish jobs in reality can be a tedious cycle, which includes building a quick and effective test system, playing out various preliminaries on it, and afterward moving the ways of behaving mastered during these preliminaries to this present reality. As a rule, in any case, the exhibition accomplished in recreations doesn’t match the one achieved in reality because of erratic changes in the climate or errands.
Scientists at the University of California, Berkeley (UC Berkeley) have as of late evolved the DayDreamer, a device that could be utilized to prepare robots to finish real jobs. Their methodology, presented in a paper pre-distributed on arXiv, depends on learning models of the world that permit robots to foresee the results of their developments and activities, lessening the requirement for broad experimentation preparation in reality.
“We needed to construct robots that constantly advance straightforwardly in reality, without establishing a recreation climate,” Danijar Hafner, one of the scientists who did the review, told TechXplore. “We had just learned world models of computer games previously, so it was really energizing to see that a similar calculation permits robots to rapidly learn in reality, as well!”
“The world model learns to first compress the sensory inputs it receives at each time step (such as motor angles, accelerometer measurements, camera images, etc.). It then learns to anticipate the representation that will be produced at the subsequent time step given a representation and a motor command.”
Danijar Hafner, one of the researchers
Utilizing their methodology, the analysts had the option to effectively and immediately help robots perform explicit ways of behaving in reality. For example, they prepared a mechanical canine to move away from its owner, stand up, and stroll in only 60 minutes.
After it was prepared, the group began pushing the robot and found that, in the span of 10 minutes, it was likewise ready to endure pushes or immediately roll into a good place again. The group likewise tried their device on automated arms, preparing them to get items and spot them in unambiguous spots without letting them know where the articles were first found.
“We saw the robots adjust to changes in lighting conditions, for example, shadows moving with the sun throughout the day,” Hafner said. Other than advancing rapidly and constantly in reality, similar calculations with no progressions functioned admirably across the four unique robots and errands. Hence, we feel that world models and online variation will play a major part in mechanical technology proceeding. “
Computational models in view of support learning can show robots ways of behaving over the long haul by giving them prizes for helpful ways of behaving, for example, great item getting a handle on systems or moving at a reasonable speed. Normally, these models are prepared through an extended experimentation process, utilizing the two recreations that can be accelerated and tested in reality.
Then again, Dreamer, the calculation created by Hafner and his partners, fabricates a world model in view of its past “encounters.” This world model can then be utilized to show robots new ways of behaving in light of “envisioned” connections. This altogether lessens the requirement for preliminaries in a genuine climate, hence considerably accelerating the preparation cycle.
“Straightforwardly foreseeing future tactile data sources would be excessively sluggish and costly, particularly when huge data sources like camera pictures are involved,” Hafner said. “The world model initially figures out how to encode its tactile contributions at each time step (engine points, accelerometer estimations, camera pictures, and so on) into a smaller portrayal. “Given a portrayal and an engine order, it then figures out how to foresee the subsequent portrayal at the following time step.”
The world model created by Dreamer permits robots to “envision” future portrayals as opposed to handling crude tactile data sources. As a result, the model can design a large number of activity groups in equal measure while utilizing a single illustration handling unit (GPU).These “envisioned” groupings help to work on the robots’ exhibition on unambiguous errands rapidly.
“The utilization of idle elements in support learning has been concentrated on widely with regards to portrayal learning; the thought being that one can make a minimal portrayal of huge tactile data sources (camera pictures, profundity checks), in this way lessening model size and maybe decreasing the preparation time required,” Alejandro Escontrela, one of the scientists engaged with the review, told TechXplore. In any case, portrayal learning methods actually expect that the robot connect with this present reality or a test system from now onward, indefinitely, for quite a while to get familiar with an errand. The Visionary, on the other hand, allows the robot to benefit from imagined connections by incorporating its learned portrayals as an exact and hyper-effective ‘test system.’This empowers the robot to play out an immense measure of preparation inside the learned world model. “
While preparing robots, Dreamer constantly gathers new encounters and uses them to upgrade its reality model, hence working on the robots’ ways of behaving. Their strategy permitted the scientists to prepare a quadruped robot to walk and adjust to explicit natural boosts in just a single hour, without utilizing a test system, which had never been accomplished.
“Later on, we envision that this innovation will empower clients to show robots numerous new abilities straightforwardly in reality, eliminating the need to plan test systems for each errand,” Hafner said. “It likewise opens the entryway for building robots that adjust to equipment disappointments, for example, having the option to stroll in spite of a wrecked engine in one of the legs.”
In their underlying tests, Hafner, Escontrela, Philip Wu, and their partners utilized their strategy to prepare a robot to get items and spot them in unambiguous spots. This errand, which is performed by human laborers in stockrooms and mechanical production systems consistently, can be hard for robots to finish, especially when the location of the items they are supposed to get is obscure.
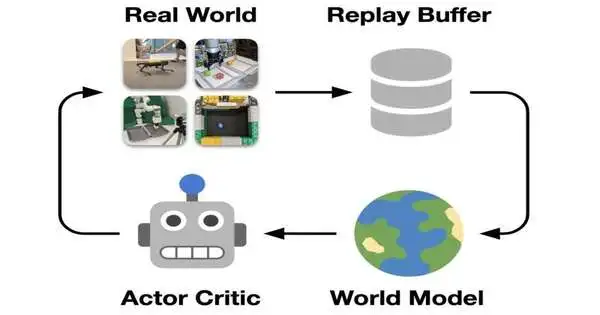
Visionary follows a basic pipeline for internet learning on actual robots without the requirement for test systems. Connection with this present reality is added to the replay cradle that stores previous encounters. A world model advances on groupings taken from the replay cradle indiscriminately. The way of behaving gains from forecasts of the world model utilizing an “entertainer pundit” calculation. The ongoing way of behaving is utilized to connect with the world and gather new encounters, closing the circle. Credit: Wu et al.
“One more trouble related to this errand is that we can’t give middle input or prize to the robot until it has really gotten a handle on something, so there is a ton for the robot to investigate without halfway direction,” Hafner said. “In 10 hours of completely independent activity, the robot prepared utilizing Dreamer moved toward the exhibition of human tele-administrators.” This outcome proposes world models as a promising methodology for robotizing stations in stockrooms and mechanical production systems. “
In their tests, the analysts effectively utilized the Dreamer calculation to prepare four morphologically different robots for different errands. Preparing these robots utilizing regular support advancement normally requires significant manual tuning, but they performed well across errands without extra tuning.
“In view of our outcomes, we are expecting that more advanced mechanics groups will begin utilizing and further developing Dreamer to tackle really testing advanced mechanics issues,” Hafner said. “Having a support learning calculation that works out of the case gives groups additional opportunity to zero in on building the robot equipment and on determining the errands they need to mechanize with the world model.”
The calculation can undoubtedly be applied to robots, and its code will before long be open source. This implies that different groups can soon utilize it to prepare their own robots utilizing world models.
Hafner, Escontrela, Wu, and their partners might now want to lead new tests, furnishing a quadruped robot with a camera so it can learn not exclusively to walk but also to recognize nearby objects. This should enable the robot to handle more difficult tasks, for example, avoiding snags, recognizing objects of interest in their current situation, or walking close to a human client.
“An open test in advanced mechanics is the way clients can naturally determine errands for robots,” Hafner added. In our work, we executed the award flags that the robot advances as Python capabilities. In any case, it would be good to show robots from human inclinations by straightforwardly letting them know when they have figured things out or wrong. This could occur by squeezing a button to give a prize or even by furnishing the robots with a comprehension of human language. “
Up to this point, the group just utilized their calculations to prepare robots for unambiguous errands, which were plainly characterized toward the start of their tests. Later on, in any case, they might likewise want to prepare robots to investigate their current circumstances without handling a plainly characterized task.
“A promising course is to train the robots to investigate their environmental factors without an errand through fake interest, and afterward adjust to tackle undertakings indicated by clients much more quickly,” Hafner added.
More information: Philipp Wu et al, DayDreamer: world models for physical robot learning. arXiv:2206.14176v1 [cs.RO], arxiv.org/abs/2206.14176





{kind=link}