Clarification strategies that help clients get it and trust AI models frequently depict how much certain elements utilized in the model add to its forecast. For instance, assuming a model predicts a patient’s gamble of creating cardiovascular illness, a doctor should know what the patient’s pulse information means for that expectation.
Yet, assuming those elements are so intricate or tangled that the client can’t grasp them, how come they end up being useful?
MIT analysts are endeavoring to work on the interpretability of elements so chiefs will be more open to utilizing the results of AI models. Based on extensive field research, they developed a scientific classification to assist designers in creating highlights that are easier for their target audience to understand.
“We discovered in the real world that, despite utilizing cutting-edge methods of describing machine-learning models, there is still a lot of confusion arising from the characteristics, not the model itself,”
Alexandra Zytek, an electrical engineering and computer science Ph.D.
“We found that out in reality, despite the fact that we were utilizing cutting-edge approaches to make sense of AI models, there is still a ton of disarray originating from the highlights, not from the actual model,” says Alexandra Zytek, an electrical design and software engineering Ph.D. understudy and lead creator of a paper presenting the scientific classification.
To construct the scientific classification, the specialists characterized properties that make highlights interpretable for five kinds of clients, from man-made reasoning specialists to individuals impacted by an AI model’s expectations. They also offer guidelines for how model makers can change highlights into designs that will be simpler for a layman to grasp.
They trust their work will move model manufacturers to consider utilizing interpretable elements from the start of the advancement cycle, instead of attempting to work in reverse and focus on logic sometime later.
Co-creators at MIT include postdoctoral researcher Dongyu Liu, visiting professor Laure Berti-Équille, research director at IRD, and senior creator Kalyan Veeramachaneni, chief examination researcher in the Laboratory for Information and Decision Systems (LIDS) and head of the Data to AI group.They are joined by Ignacio Arnaldo, a key information researcher at Corelight. The examination is distributed in the June version of the Association for Computing Machinery Special Interest Group on Knowledge Discovery and Data Mining’s friend audited Explorations Newsletter.
Real-world lessons
Highlights are input factors that are taken care of by AI models; they are normally drawn from the segments in a dataset. Information researchers commonly select and handcraft highlights for the model, and they mostly center around guaranteeing highlights are created to work on model exactness, not on whether a chief can comprehend them, Veeramachaneni makes sense of.
For a long time, he and his group have worked with chiefs to recognize AI ease of use difficulties. These area specialists, most of whom need AI information, frequently have no faith in models since they don’t grasp the elements that impact forecasts.
For one task, they cooperated with clinicians in a clinic ICU who utilized AI to foresee the chance a patient would confront confusion after a heart medical procedure. A few elements were introduced as total values, similar to the pattern of a patient’s pulse over the long run. While highlights coded this way were “model prepared” (the model could handle the information), clinicians didn’t see how they were figured. They would prefer to perceive how these collected elements connect with unique qualities so they could recognize oddities in a patient’s pulse, Liu says.
Conversely, a gathering of learning researchers favored highlights that were totaled. Rather than having an element like “number of posts an understudy made on conversation gatherings,” they would prefer to have related highlights gathered and named with terms they grasped, similar to “support.”
“With interpretability, one size doesn’t fit all. When you go from one region to another, there are various necessities. Also, interpretability itself has many levels, “Veeramachaneni says.”
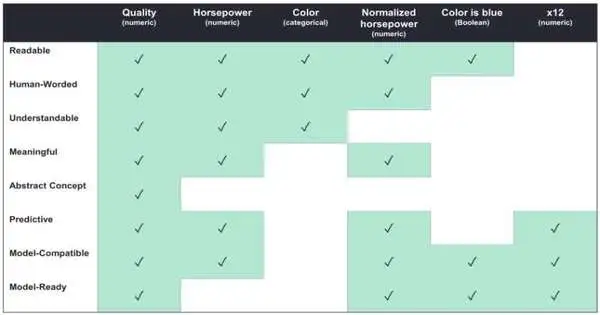
The possibility that one size doesn’t fit everything is vital to the analysts’ scientific classification. They define properties that make them easily interpretable for various leaders and layout which properties are generally important to explicit clients.
For example, AI designers could zero in on having highlights that are viable with the model and prescient, meaning they are supposed to work on the model’s exhibition.
Then again, chiefs with no AI experience may be ideally serviced by highlights that are human-phrased, meaning they are depicted in a way that is normal for clients and justifiable, meaning they allude to true measurements clients can reason about.
According to the scientific categorization, assuming you are making interpretable elements, to what extent would they say they are interpretable? You may not require all levels, contingent upon the kind of space specialists you are working with, “Zytek says.”
Putting interpretability first
The scientists also frame design methods that a designer can use to make it more interpretable for a specific audience.
Highlight designing is a cycle where information researchers change information into a configuration AI models can process, utilizing methods like totaling information or normalizing values. Most models, likewise, can’t handle all the information except if they are changed over completely to a mathematical code. These changes are frequently almost unthinkable for laypeople to accept.
Zytek says that making interpretable elements could include fixing a portion of that encoding. For example, a typical element design method coordinates ranges of information so they all contain a similar number of years. To make these elements more understandable, age ranges could be classified using human terms such as baby, child, and adolescent. on the other hand, instead of utilizing a changed element like normal heartbeat rate, an interpretable component could just be the real heartbeat rate information, Liu adds.
“In a ton of spaces, the tradeoff between interpretable elements and model exactness is tiny. At the point when we were working with kid government assistance screeners, for instance, we retrained the model involving just elements that met our definitions for interpretability, and the exhibition decline was practically immaterial, “Zytek says.”
Working off this work, the scientists are fostering a framework that empowers a model designer to deal with muddled highlight changes in a more effective way and to make human-focused clarifications for AI models. This new framework will also transform calculations intended to make sense of model-prepared datasets into designs that chiefs can perceive.
More information: The Need for Interpretable Features: Motivation and Taxonomy. kdd.org/exploration_files/vol2 … e_Spaces_revised.pdf




