Biomedical specialists at Duke College have fostered another strategy to work on the viability of AI models. By matching two AI models, one to accumulate information and one to investigate it, specialists can evade restrictions on innovation without sacrificing precision.
This new strategy could make it more straightforward for scientists to utilize AI calculations to recognize and portray atoms for use in expected new therapeutics or different materials.
The exploration is distributed in the diary of computerized reasoning in the Existence Sciences.
In conventional AI models, a specialist will enter a dataset, and the model will utilize that data to make forecasts. While this is often compelling, the capacities of these apparatuses are restricted by the datasets that are utilized to prepare them, which may frequently need key data or incorporate a lot of one type of information, bringing inclination into the model.
All things being equal, scientists have fostered a procedure known as dynamic AI, where the model can clarify pressing issues or solicit more data in the event that it detects a hole in the information. This scrutinizing capacity makes the model more precise and productive than its uninvolved partner.
Although dynamic learning is profoundly powerful for AI models, the procedure experiences serious restrictions when it’s applied to more complicated, profound brain organizations. Intended to emulate the human cerebrum, these profound learning models expect definitely a greater amount of information—and registering power—than is in many cases accessible, restricting their exactness and viability.
“We sought to determine whether we could use an active machine learning model to ‘teach’ another model using the data that the actively learning model considers important. An active machine learning model is able to sift through a dataset, identify the important information, and request any missing information it deems significant.”
Reker
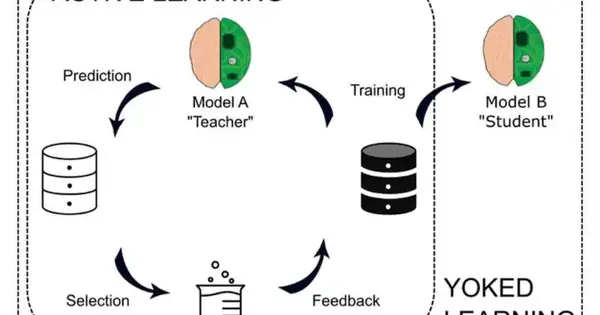
Reker and his group needed to decide whether an instructive idea known as “burdened learning” could be applied to the universe of AI to work on these frameworks.
During burdened learning, one understudy will effectively learn content. They can get clarification on some pressing issues and really look at the changed course readings for missing data. A subsequent understudy will then, at that point, be entrusted to survey the data the principal understudy considered critical to figure out the example. While investigations of burdened learning have shown that the subsequent understudy frequently neglects to learn ideas and hold information as effectively as the learning understudy, Reker accepted the strategy-held guarantee in AI.
“A functioning AI model knows how to go through a dataset and recognize the significant data, yet in addition, it demands any missing data it believes is critical,” said Reker. “We needed to check whether we could utilize that dynamic AI model to ‘educate’ another model utilizing the information the effective learning model considers significant.”
To comprehend how burdened AI contrasted with dynamic AI, the group had an effective learning model that recognized various qualities of sub-atomic mixtures that are significant for its prosperity, like the expected harmfulness of the particle and the particle’s digestion. A burdened framework was created by matching unique “educating” AI models with various “understudy” AI models to distinguish similar qualities in light of the information chosen by the “educating” model.
The group found that while dynamic AI was more precise than the burdened framework, generally speaking, the burdened models were extremely powerful under specific boundaries.
“We saw that the showing model’s exhibition was vital for the understudy models,” made sense of Reker. “Very much like, in actuality, an ineffectual educator implies that the understudy isn’t in a good position. In the event that the showing model didn’t distinguish helpful information, the understudy model wasn’t as fruitful at unraveling it.”
These outcomes persuaded Reker and his group to test burdened learning with a profound brain network model as the “understudy,” named Burdened Profound Learning, or Warble. Dissimilar to a functioning profound learning model, where the profound brain network itself is liable for choosing the information, Warble has another dynamic AI calculation go about as the “educator” to direct the information security for the profound brain organization “understudy effectively.”
In a few correlations concentrating on utilizing various models, the group found that their Warble method either beat or was similarly pretty much as exact as a functioning profound learning framework while recognizing different sub-atomic qualities. They likewise observed that Warble was a lot quicker, frequently just requiring a couple of moments to follow through with a responsibility, while profound dynamic learning would require hours or even days.
The group has recorded a temporary patent on the Warble procedure, yet they as of now have plans to proceed to test and work on the boundaries of the model as well as involving it in reality.
“There are bunches of various AI and profound brain network models, so we need to figure out what matches coordinate all around well for this burdened learning,” said Reker. “Warble’s capacity to tackle the qualities of old-style AI models to upgrade the viability of profound brain networks makes this an extremely thrilling device in a field that is continuously developing. We are hopeful that we and different researchers can involve this apparatus sooner rather than later to assist with finding new medications and new medication conveyance arrangements.”
More information: Zhixiong Li et al, Yoked learning in molecular data science, Artificial Intelligence in the Life Sciences (2023). DOI: 10.1016/j.ailsci.2023.100089




