Human-PC gaming has a long history and has been a primary device for confirming key man-made reasoning innovations. The Turing test, proposed in 1950, was the principal human-PC game to decide whether a machine has human knowledge. This has propelled analysts to foster man-made intelligence frameworks (AIs) that can challenge proficient human players.
A normal model is a checker’s simulated intelligence called Chinook, which was created in 1989 to overcome the best on the planet. The objective was accomplished when it beat Marion Tinsley in 1994. Afterward, Dark Blue from IBM beat chess grandmaster Garry Kasparov in 1997, setting another time throughout the entire existence of human-PC gaming.
Lately, analysts have seen the fast advancement of human-PC gaming AIs, from the DQN specialists AlphaGo, Libratus, and OpenAI Five to AlphaStar. These AIs can overcome proficient human players in specific games with a mix of current methods, showing a major move toward dynamic knowledge.
For instance, AlphaGo Zero, which utilizes Monte Carlo tree search, self-play, and profound learning, routs many expert go players, addressing strong methods for enormously wonderful data games. OpenAI Five, utilizing self-play, profound support learning, and ceaseless exchange through a medical procedure, turned into the main man-made intelligence to beat the title holders at an eSports game, showing helpful strategies for complex, flawed data games.
After the progress of AlphaStar and OpenAI Five, which arrive at the expert human player level in the games StarCraft and Dota 2, separately, it appears that ongoing procedures can address extremely complex games. Particularly the leap forward of the latest human-PC gaming AIs for games, for example, the Distinction of Lords and Mahjong, complies with comparable structures of AlphaStar and OpenAI Five, showing a specific level of comprehensiveness of current methods.
All in all, one regular inquiry emerges: What are the potential difficulties of current strategies in human-PC gaming, and what are the patterns to come? Another paper distributed in Machine Knowledge Exploration expects to survey late-fruitful human-PC gaming AIs and attempts to respond to the inquiry through an exhaustive examination of current strategies.
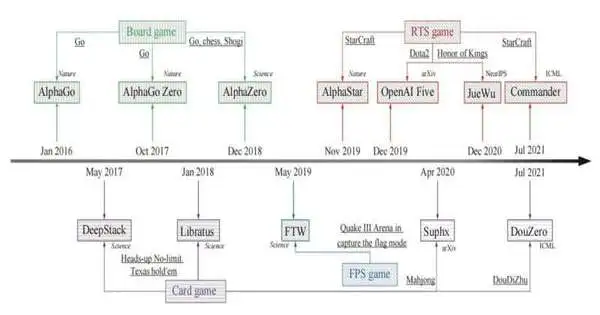
In light of the momentum leap forward of human-PC gaming AIs (most distributed in diaries like Science and Nature), analysts review four ordinary sorts of games, i.e., prepackaged games with Go; games, for example, heads-up no-restriction Texas hold′em (HUNL), DouDiZhu, and Mahjong; first individual shooting match-ups (FPS) with Shudder III Field in Catch the Banner (CTF); continuous system games (RTS) with StarCraft, Dota2, and Distinction of Lords. The related AIs cover AlphaGo, AlphaGo Zero, AlphaZero, Libratus, DeepStack, DouZero, Suphx, FTW, AlphaStar, OpenAI Five, JueWu, and Officer.
The rest of the paper is coordinated as follows: In Area 2, specialists portray the games and AIs shrouded in this paper. In view of the new advancement of human-PC gaming AIs, this paper audits four kinds of games and their comparing AIs, i.e., table games, games, FPS games, and RTS games. To quantify how hard a game is to foster proficient human-level simulated intelligence, specialists remove a few key factors that challenge wise direction, which are flawed data, a long-term skyline, an in-transitive game, and multi-specialist collaboration.
Area 3 is about table game AIs. The AlphaGo series is constructed in light of Monte Carlo tree search (MCTS), which has been broadly used in past Go projects. AlphaGo turned out in 2015 and beat European Go hero Fan Hui, which was whenever that man-made intelligence first won against proficient players in a regular game, Do without Renzi. A while later, a high-level rendition called AlphaGo Zero was created utilizing different learning systems, which needs no earlier expert human showdown information and arrives at godlike execution. AlphaZero utilizes a comparable learning structure to AlphaGo Zero and investigates an overall support learning calculation, which experts Oblige another two prepackaged games, chess and shogi.
Segment 4 presents game AIs. The game, as a commonplace in-wonderful data game, has been quite difficult for man-made reasoning. DeepStack and Libratus are two average computer-based intelligence frameworks that rank proficient poker players in HUNL. They share a similar essential method, i.e., counterfactual lament minimization (CFR). Subsequently, specialists are zeroing in on Mahjong and DouDiZhu, which raise new difficulties for man-made reasoning. Suphx, created by Microsoft Exploration Asia, is the principal man-made intelligence framework that beats most top human players in Mahjong. DouZero, intended for DouDiZhu, is a man-made intelligence framework that was positioned first on the Botzone list of competitors among 344 computer-based intelligence specialists.
First-individual shooting match-up AIs are displayed in Segment 5. CTF is a regular three-layered multiplayer first-individual computer game in which two rival groups are battling against one another on indoor or outdoor maps. The settings for CTF are totally different from the current multiplayer computer games. All the more explicitly, specialists in CTF can’t get to the condition of different players, and specialists in a group can’t speak with one another, making this climate a generally excellent testbed for learning specialists to arise correspondence and adjust to zero-shot age. Zero-shot implies that a specialist who participated or went up against isn’t the specialist prepared, which can be human players and inconsistent man-made intelligence specialists. Dependent exclusively upon pixels and game focuses like a human as information, the learned specialist FTW arrives at areas of strength for a level exhibition.
Area 6 is about the RTS game. The RTS game, as a run-of-the-mill sort of computer game with a huge number of individuals battling against one another, normally turns into a testbed for human-PC gaming. Besides, RTS games for the most part have a mind-boggling climate, which captures a greater amount of the idea of this present reality than past games, making the forward leap of such games more relevant. AlphaStar, created by DeepMind, utilizes general learning calculations and arrives at the grandmaster level for every one of the three races in StarCraft, which additionally beats 99.8% of human players who are dynamic on the European server. Commandant, as a lightweight calculation rendition, follows a similar learning engineering as AlphaStar, which utilizes a significant degree less calculation and beats two grandmaster players on a live occasion. OpenAI Five expects to address the Dota2 game, which is the main simulated intelligence framework to overcome the title holders in an eSports game. As a generally comparable eSports game to Dota 2, Distinction of Rulers shares the most comparative difficulties, and JueWu turns into the primary man-made intelligence framework that can play full RTS games as opposed to confining the legend pool.
In Area 7, specialists sum up and analyze the various strategies used. In view of the flow-forward leap of human-PC gaming AIs, as of now, methods can be generally isolated into two classifications, i.e., tree search (TS) with self-play (SP) and conveyed profound support learning (DDRL) with self-play or populace play (PP). It ought to be noticed that scientists simply notice the fundamental or key methods in every class, in light of which various AIs for the most part acquire other key modules in view of the games, and those new modules are now and again not nonexclusive across games. The tree search has two sorts of delegate calculations: MCTS, generally utilized for wonderful data games, and CFR, customarily intended for flawed data games. Concerning populace play, it is utilized for three circumstances: various players or specialists don’t have a similar strategy network because of the game qualities; populaces can be kept up with to conquer the game hypothetical difficulties, for example, non-transitivity; populaces are joined with populace-based preparation to learn versatile specialists. With the examination, scientists talk about two focuses as follows: how to arrive at Nash balance and how to become general innovators.
In Segment 8, specialists show the difficulties in momentum game AIs, which might be the future examination heading of this field. Despite the fact that huge headway has been made in human-PC gaming, current methods have somewhere around one of three impediments. Most AIs, right off the bat, are intended for a particular human-PC game or a guide of a particular game, and the AIs learned can’t be involved in any event for various guides of a game. Besides, insufficient investigations are performed to approve the AI′s capacity when an unsettling influence is brought into the game. Besides, preparing the above AIs requires countless calculation assets. Because of the immense equipment asset edge, just a set number of associations are fit for preparing undeniable-level AIs, which will deter most logical exploration from an inside-out investigation of the issue. Thirdly, most AIs are considered in light of their triumphant capacity in contrast to restricted proficient human players, and a case of arriving at the master level might be somewhat misrepresented. The expected headings and difficulties faced by the above restrictions are introduced in this part.
This paper sums up and analyzes procedures for the current leap forward of AIs in human-PC gaming. Through this overview, specialists trust that amateurs can immediately get comfortable with the methods, difficulties, and valuable open doors in this thrilling field, and analysts on the way can be motivated for more profound review.
More information: Qi-Yue Yin et al. AI in Human-Computer Gaming: Techniques, Challenges, and Opportunities, Machine Intelligence Research (2023). DOI: 10.1007/s11633-022-1384-6




