Enormous language models (LLMs) are profound learning calculations that can cycle composed or spoken prompts and create texts in light of these prompts. These models have, as of late, become progressively well known and are currently assisting numerous clients with making outlines of long reports, gaining motivation for brand names, tracking down fast responses to basic inquiries, and producing different sorts of texts.
Researchers from the Mayo Clinic and the University of Georgia recently set out to evaluate the biological knowledge and reasoning abilities of various LLMs. Their paper, pre-distributed on the arXiv server, recommends that OpenAI’s model GPT-4 performs better compared to the next dominating LLMs available on thinking science issues.
“Our new distribution is a demonstration of the critical effect of man-made intelligence on natural exploration,” Zhengliang Liu, co-creator of the new paper, told Tech Xplore. “This study was conceived out of the fast reception and advancement of LLMs, particularly following the striking presentation of ChatGPT in November 2022. These headways, seen as basic strides towards counterfeit general knowledge (AGI), denoted a shift from customary biotechnological ways to dealing with a computer-based intelligence-centered philosophy in the domain of science.”
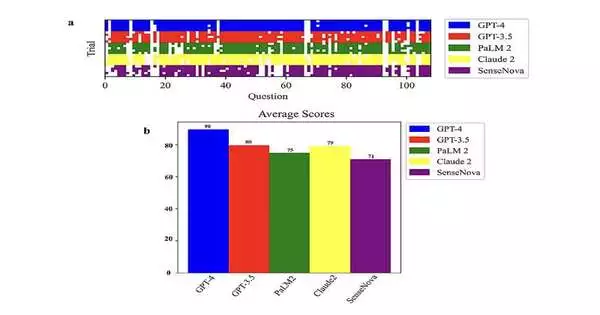
“The key goals of this research were to evaluate and compare the skills of top LLMs, such as GPT-4, GPT-3.5, PaLM2, Claude2, and SenseNova, in understanding and reasoning through biology-related problems. A 108-question multiple-choice exam covering varied disciplines such as molecular biology, biological methods, metabolic engineering, and synthetic biology was used to rigorously analyze this.”
Zhengliang Liu, co-author of the recent paper,
In their new review, Liu and his partners set off on a mission to all the more likely grasp the possible worth of LLMs as devices for directing examination in science. While many past examinations stressed the utility of these models in a large number of spaces, their capacity to reason about organic information and ideas has not yet been assessed from top to bottom.
“The essential goals of this paper were to evaluate and look at the capacities of driving LLMs, for example, GPT-4, GPT-3.5, PaLM2, Claude2, and SenseNova, in their capacity to understand and reason through science-related questions,” Liu said. “This was carefully assessed utilizing a 108-question different decision test, covering assorted regions like sub-atomic science, natural strategies, metabolic design, and manufactured science.”
Liu and his colleagues wanted to find out how some of the most well-known LLMs that are currently available process and analyze biological data. They also wanted to see how well they could come up with relevant biological hypotheses and do logical reasoning tasks related to biology. The specialists analyzed the presentation of five unique LLMs utilizing different decision tests.
“Various decision tests are normally utilized for assessing LLMs in light of the fact that the experimental outcomes can be effectively reviewed, assessed, and analyzed,” Jason Holmes, co-creator of the paper, made sense of. “For this review, science specialists planned a 108-question different decision test with a couple of subcategories.”
Holmes and their associates posed LLMs for every one of the inquiries in the test they accumulated multiple times. Each time an inquiry was posed, be that as it may, they changed the way things were stated.
“The reason for posing similar inquiries on different occasions for every LLM was to decide both the normal execution and the typical variety in replies,” Holmes made sense of. “We shifted the expression so as not to unintentionally put together our outcomes with respect to an ideal or less than ideal statement of guidelines that prompted an adjustment of execution. This approach additionally provides us with a thought of how the presentation will differ in genuine utilization, where clients won’t pose inquiries similarly.”
The tests done by Liu, Holmes, and their partners assembled an understanding of the expected utility of various LLMs for helping science specialists. In general, their outcomes recommend that LLMs answer well to different science-related questions while likewise precisely relating ideas established in basic sub-atomic science, normal atomic science, metabolic design, and manufactured science.
“Strikingly, GPT-4 exhibited prevalent execution among the inspected LLMs, accomplishing a typical score of 90 on our numerous decision tests across five preliminaries using unmistakable prompts,” Xinyu Gong, co-creator of the paper, said.
“Past achieving the most elevated test score by and large, GPT-4 additionally shown extraordinary consistency across the preliminaries, featuring its dependability in science thinking compared with peer models. These discoveries stress GPT-4’s monstrous ability to help science exploration and schooling.”
The new concentrate by this group of scientists could before long motivate extra work that further investigates the convenience of LLMs in the area of science. The outcomes accumulated so far recommend that LLMs could be valuable instruments for both exploration and training, for example, supporting the coaching of understudies on science, the production of intelligent learning devices, and the making of testable natural speculations.
“Fundamentally, our paper addresses a spearheading exertion in consolidating the capacities of cutting-edge computer-based intelligence, especially LLMs, with the complicated and quick-developing area of science,” Liu said. “It denotes another section in organic examination, situating artificial intelligence as a strong device yet as a focal component in exploring and unraveling the immense and complex natural scene.”
The future progression of LLMs and their further preparation on organic information could make them ready for significant logical revelations while additionally empowering the production of further developed instructive apparatuses. More research in this area is now planned by Liu, Holmes, Gong, and their colleagues.
In their next work, they first intend to devise techniques to beat the computational requests and protection-related issues related to the utilization of GPT-4, the LLM supporting ChatGPT. This could be accomplished by creating open-source LLMs to automate errands, for example, quality explanation and aggregate genotype matching.
“We’ll utilize information refining from GPT-4, making guidance following information to tweak neighborhood models, for example, the LLaMA establishment models,” Zihao Wu, co-creator of the paper, told Tech Xplore.
“This system will use GPT-4’s abilities while tending to security and cost concerns, making progressed apparatuses more available to the science local area. Furthermore, with GPT-4V’s vision abilities, we’ll stretch out our examination to multimodal investigations, zeroing in on normal medication atoms, like enemy of disease specialists or antibody adjuvants, especially those with obscure biosynthetic pathways.”
“We’ll research their compound and biosynthetic pathways and expected applications. GPT-4V’s capacity to perceive atomic designs will improve our examination of complex multimodal information, propelling our comprehension and application in drug disclosure and advancement in manufactured science.”
More information: Xinyu Gong et al, Evaluating the Potential of Leading Large Language Models in Reasoning Biology Questions, arXiv (2023). DOI: 10.48550/arxiv.2311.07582




