In the quickly arising universe of enormous scope registration, it was inevitable before a game-changing accomplishment was ready to stir up the field of 3D representations.
Adobe Exploration and the Australian Public College (ANU) have reported the main man-made consciousness model fit for producing 3D pictures from a single 2D picture.
In an improvement that will change 3D model creation, scientists say their new calculation, which trains on monstrous samplings of pictures, can produce such 3D pictures in no time.
“By combining a high-capacity model with large-scale training data, we are able to make our model highly generalizable and produce high-quality 3D reconstructions from a variety of testing inputs.”
Hong, the lead author of a report on the project,
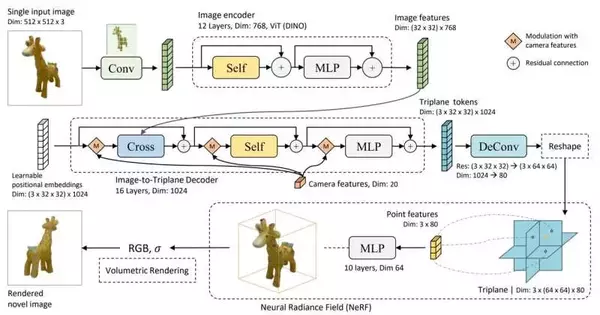
Yicong Hong, an Adobe understudy and previous alumni understudy of the School of Designing, Registering, and Computer Science at ANU, said their enormous recreation model (LRM) depends on an exceptionally versatile brain network containing 1,000,000 datasets with 500 million boundaries. Such datasets incorporate pictures, 3D shapes, and recordings.
“This blend of a high-limit model and huge scope for preparing information engages our model to be profoundly generalizable and produce top-notch 3D reproductions from different testing inputs,” Hong, the lead creator of a report on the task, said.
“Supposedly, [our] LRM is the primary huge-scope 3D remaking model.”
Expanded reality and computer-generated reality frameworks, gaming, realistic liveliness, and a modern plan can be anticipated to exploit the groundbreaking innovation.
Mid-3D imaging programming did well just in unambiguous subject classifications with pre-laid-out shapes. Hong made sense of the fact that later advances in the picture age were accomplished with projects like DALL-E and Stable Dispersion, which “utilized the momentous speculation capacity of 2D dissemination models to empower multi-sees.” Nonetheless, results from those projects were restricted to pre-prepared 2D generative models.
Different frameworks use per-shape enhancement to accomplish great outcomes; however, they are “frequently sluggish and unrealistic,” as indicated by Hong.
The development of normal language models inside huge transformer networks that used enormous scope information to expand next-word expectation errands, Hong said, urged his group to pose the inquiry, “Is it conceivable to get familiar with a conventional 3D earlier for recreating an item from a single picture?”
Their response was “yes.”
“LRM can remake high-loyalty 3D shapes from a great many pictures caught in reality, as well as pictures made by generative models,” Hong said. “LRM is likewise an exceptionally commonsense answer for downstream applications since it can create a 3D shape in only five seconds without post-enhancement.”
The program’s prosperity lies in its capacity to draw upon its data set of millions of picture boundaries and foresee a brain brilliance field (NeRF). That is the ability to produce sensible-looking 3D symbolism dependent exclusively upon 2D pictures, regardless of whether those photos are low-goal. NeRF has picture blend, object discovery, and picture division abilities.
It was quite a while ago that the main PC program that permitted clients to produce and control straightforward 3D shapes was made. Sketchpad, planned by Ivan Sutherland as a feature of his Ph.D. proposal at MIT, had a sum of 64K of memory.
Throughout the long term, 3D projects developed huge amounts at a time, with such projects as AutoCAD, 3D Studio, SoftImage 3D, RenderMan, and Maya.
Hong’s paper, “LRM: Huge Remaking Model for Single Picture to 3D,” was transferred to the preprint server arXiv on Nov. 8.
More information: Yicong Hong et al., LRM: Large Reconstruction Model for Single Image to 3D, arXiv (2023). DOI: 10.48550/arxiv.2311.04400
Project page: yiconghong.me/LRM/




