Late headways in the field of AI (ML) have extraordinarily worked on the nature of programmed interpretation devices. As of now, these devices are principally used to interpret fundamental sentences, as well as short messages or informal reports.
Artistic texts, like books or brief tales, are still completely deciphered by master human interpreters, who are knowledgeable about getting a handle on conceptual and complex implications and interpreting them in another dialect. While a couple of studies have explored the capability of computational models for deciphering scholarly texts, discoveries in this space are as yet restricted.
Scientists at UMass Amherst have as of late completed a review investigating the nature of scholarly text interpretations delivered by machines, by contrasting them and same text-interpretations made by people. Their discoveries, pre-distributed on arXiv, feature a portion of the weaknesses of existing computational models to make an interpretation of unfamiliar texts into English.
“Machine translation (MT) has the potential to supplement human translators’ work by improving both training procedures and overall efficiency. Literary translation is less constrained than more traditional MT settings because translators must balance meaning equivalence, readability, and critical interpretability in the target language. This property, combined with the complex discourse-level context present in literary texts, also makes literary MT more challenging.”
Katherine Thai and her colleagues wrote in their paper.
“Machine interpretation (MT) holds potential to supplement crafted by human interpreters by further developing both preparation strategies and their general productivity,” Katherine Thai and her partners wrote in their paper. “Artistic interpretation is less compelled than more customary MT settings since interpreters should adjust meaning comparability, comprehensibility, and basic interpretability in the objective language. This property, alongside the complicated talk level setting present in abstract messages, likewise makes artistic MT more testing to computationally demonstrate and assess.”
The critical goal of the new work by Thai and her partners was to more readily comprehend the manners by which cutting edge MT devices actually bomb in the interpretation of artistic texts when contrasted with human interpretations. Their expectation was that this would assist with recognizing explicit regions that engineers ought to zero in on to work on these models’ exhibition.
“We gather a dataset (PAR3) of non-English language books in the public space, each adjusted at the passage level to both human and programmed English interpretations,” Thai and her partners made sense of in their paper.
PAR3, the new dataset assembled by the analysts for the extent of their review, contains 121,000 passages extricated from 118 books initially written in various dialects other than English. For every one of these passages, the dataset incorporates a few different human interpretations, as well as an interpretation delivered by Google decipher.
The specialists analyzed the nature of human interpretations of these artistic passages with the ones delivered by Google decipher, involving normal measurements for assessing MT instruments. Simultaneously, they asked master human interpreters which interpretations they liked, while additionally inciting them to distinguish issues with their most un-favored interpretation.
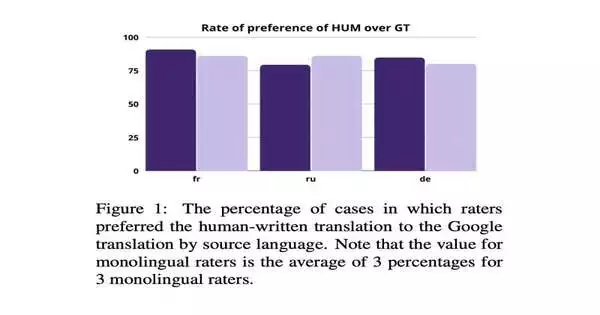
“Utilizing PAR3, we find that master scholarly interpreters lean toward reference human interpretations over machine-deciphered passages at a pace of 84%, while best in class programmed MT measurements don’t connect with those inclinations,” Thai and her partners wrote in their paper. “The specialists note that MT yields contain mistranslations, yet additionally talk upsetting mistakes and expressive irregularities.”
Basically, the discoveries accumulated by Thai and her partners propose that measurements to assess MT (e.g., BLEU, BLEURT, and BLONDE) probably won’t be especially successful, as human interpreters disagreed with their forecasts. Quite, the input they accumulated from human interpreters likewise permitted the analysts to recognize explicit issues with interpretations made by Google decipher.
Involving the human specialists’ input as a rule, the group eventually made a programmed post-altering model in light of GPT-3, a profound learning approach presented by an exploration bunch at OpenAI. They found that master human interpreters favored the scholarly interpretations created by this model at a pace of 69%.
Later on, the discoveries of this study could illuminate new investigations investigating the utilization of MT devices to decipher artistic texts. Likewise, the PAR3 dataset gathered by Thai and her associates, which is currently openly accessible on GitHub, could be utilized by different groups to prepare or survey their language models.
“In general, our work uncovers new difficulties to advance in scholarly MT, and we trust that the public arrival of PAR3 will urge scientists to handle them,” the analysts deduced in their paper.
More information: Katherine Thai et al, Exploring Document-Level Literary Machine Translation with Parallel Paragraphs from World Literature, arXiv (2022). DOI: 10.48550/arxiv.2210.14250
Journal information: arXiv




