Looking through the web can uncover data a client would prefer to keep hidden. For example, when somebody looks into clinical side effects on the web, they could uncover their ailments through research, an internet-based clinical data set like WebMD, and maybe many of these organizations’ sponsors and colleagues.
For a long time, scientists have been developing procedures that allow clients to search for and recover data from a data set invisibly, but these techniques are far too late to be successfully used in the future.
MIT specialists have now developed a plan for private data recovery that is multiple times quicker than other practically identical techniques. Their strategy empowers a client to look through a web-based data set without revealing their question to the server. Also, determined by a straightforward calculation would be simpler to execute than the more convoluted comes nearer from past work.
“This effort is primarily concerned with restoring users’ control over their own data. In the long run, we want online browsing to be as private as going to the library. This work does not yet achieve that, but it does begin to construct the tools that will allow us to execute this type of thing fast and efficiently in practice.”
Alexandra Henzinger, a computer science graduate student
Their method could empower private correspondence by preventing an informing application from understanding what clients are talking about or who they are conversing with. It could likewise be utilized to get important web-based promotions without disclosing servers’ advantages to clients.
“This work is truly about giving clients back some command over their own information. Over the long haul, we’d like perusing the web to be essentially as private as perusing a library. “This work doesn’t accomplish that yet, yet it begins fabricating the devices to allow us to do something like this rapidly and proficiently, practically speaking,” says Alexandra Henzinger, a software engineering graduate understudy and lead creator of a paper presenting the strategy.
Safeguarding protection
The principal plans for private data recovery were created during the 1990s, mostly by scientists at MIT. These strategies empower a client to speak with a far-off server that holds a data set and read records from that information base without the server understanding what the client is perusing.
To safeguard security, these methods force the server to contact each and every item in the data set, so it can’t see which passage a client is looking for. Assuming one region is left immaculate, the server would discover that the client isn’t keen on that thing. Be that as it may, contacting each item when there might be a great many information base sections dials back the inquiry interaction.
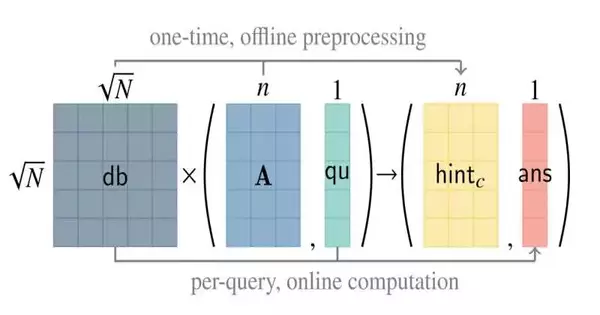
To speed things up, the MIT specialists fostered a convention known as “straightforward PIR,” in which the server performs a significant part of the hidden cryptographic work ahead of time, before a client even sends a question. This preprocessing step delivers an information structure that holds compacted data about the data set items and which the client downloads prior to sending a question.
One might say that this information structure resembles a clue for the client about what is in the data set.
“When the client has this clue, it can make an unbounded number of inquiries, and these inquiries will be a lot more modest in both the size of the messages you are sending and the work that you want the server to do.” “This simplifies PIR so much faster,” Henzinger says.
Be that as it may, the clue can be somewhat enormous in size. For instance, to inquire about a 1-gigabyte information base, the client would have to download a 124-megabyte hint. This drives up correspondence costs, which could make the method difficult to carry out on genuine gadgets.
To diminish the size of the clue, the scientists developed a subsequent method, known as “twofold PIR,” that fundamentally includes running the Straightforward PIR experiment two times. This delivers a substantially more minimal clue that is fixed in size for any data set.
Using Double PIR, the clue for a 1 gigabyte data set is only 16 megabytes.
“Our twofold PIR plot runs somewhat slower, yet it will have a lot lower correspondence costs.” “For certain applications, this will be a helpful tradeoff,” Henzinger says.
Stirring things up around the town limit
They tested the Basic PIR and Twofold PIR plans by applying them to a task in which a client wants to review a specific piece of data about a site to ensure that site is safe to visit.To save protection, the client can’t uncover the site it is evaluating.
The specialists’ quickest procedure had the option to effectively save security while running at around 10 gigabytes per second. Past plans could accomplish a throughput of around 300 megabytes per second.
They demonstrate that their strategy approaches the theoretical speed limit for private data recovery—it is nearly the quickest plot in which the server contacts each record in the data set, adds Corrigan-Gibbs.
Likewise, their strategy just requires a solitary server, making it a lot more straightforward than many top-performing procedures that require two separate servers with indistinguishable information bases. Their strategy outperformed these more complex conventions.
“I’ve been contemplating these plans for quite a while, and I never figured this could be conceivable at this speed.” The fable was that any single-server conspiracy would be truly sluggish. “This work turns that entire idea on its head,” Corrigan-Gibbs says.
While the scientists have demonstrated how they can speed up PIR conspiracies, there is still work to be done before they can apply their methods in real-world situations, according to Henzinger.They may wish to reduce their plans’ correspondence costs while still allowing them to achieve high velocities.Furthermore, they need to adjust their procedures to deal with additional mind-boggling questions, for example, general SQL inquiries, and additional requests, for example, an overall Wikipedia search. What’s more, over the long haul, they desire to foster improved methods that can protect security without requiring a server to contact each information base item.
“I’ve heard individuals unequivocally asserting that PIR won’t ever be functional. Yet I could never wager against innovation. That is a hopeful illustration to gain from this work. “There are consistently ways to improve,” says senior creator Vinod Vaikuntanathan, an EECS teacher and head agent in CSAIL.
“This work makes a significant improvement to the commonsense expense of private data recovery.” While it was realized that low-data transmission PIR plans suggest public-key cryptography, which is commonly significant degrees slower than private-key cryptography, this work fosters a cunning technique to overcome any barrier. This is finished by utilizing the exceptional properties of a public-key encryption plot because of Regev’s decision to push by far most of the computational work to a precomputation step, in which the server processes a short “hint” about the data set,” says Yuval Ishai, a teacher of software engineering at Technion (the Israel Foundation for Innovation), who was not engaged with the review.
“It makes their methodology especially engaging that a similar clue can be utilized an unlimited number of times by quite a few clients.” This provides the low cost of registering the clue as unimportant in a typical situation where a similar data set is obtained routinely.
More information: Paper: One Server for the Price of Two: Simple and Fast Single-Server Private Information Retrieval





{kind=link}