A new model that trains four-legged robots to see more clearly in three dimensions has been developed by researchers at the University of California, San Diego. This new model allowed a robot to easily and autonomously cross difficult terrain, such as stairs, rocky ground, and gaps in paths, while removing obstacles in its path.
At the 2023 Conference on Computer Vision and Pattern Recognition (CVPR), which will be held in Vancouver, Canada, from June 18 to 22, the researchers will present their findings.
“By giving the robot a better understanding of its surroundings in 3D, it can be deployed in more complex real-world environments,”
Senior author Xiaolong Wang, a professor of electrical and computer engineering at the UC San Diego Jacobs School of Engineering.
“By furnishing the robot with a superior comprehension of its environmental factors in 3D, it very well may be sent in additional complicated conditions in reality,” said concentrate on senior creator Xiaolong Wang, a teacher of electrical and PC designing at the UC San Diego Jacobs School of Designing.
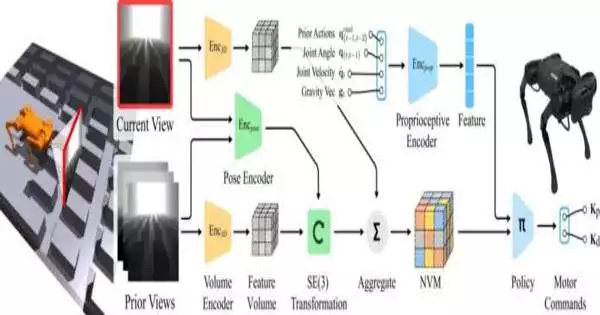
The robot is furnished with a front-oriented depth camera on its head. The camera has a good view of both the scene in front of it and the ground below it because it is angled down.
A model that converts two-dimensional images from the camera into three-dimensional space was developed by the researchers to enhance the robot’s ability to perceive three dimensions. It accomplishes this by first looking at a brief video sequence that includes the current frame as well as a few frames from before it, and then taking bits of 3D information from each 2D frame. This includes information about the robot’s leg movements, such as its distance from the ground, joint velocity, and joint angle. To estimate the 3D transformation between the past and the present, the model makes a comparison between the data from the previous frames and the data from the current frame.
In order to use the current frame to synthesize the previous frames, the model combines all of that data. The model compares the synthesized frames to the frames that the camera has already captured as the robot moves. The model is aware that it has learned the correct representation of the 3D scene if they are a good match. In any case, it makes revisions until it takes care of business.
The robot’s movement is controlled by the 3D representation. The robot can remember what it has seen and what its legs have done in the past by combining visual information from the past and using that memory to plan its next moves.
Wang stated, “Our approach enables the robot to build a short-term memory of its 3D surroundings so it can act better.”
The team’s previous work, in which they developed algorithms that enable a four-legged robot to walk and run on uneven ground while avoiding obstacles, is the foundation for the new study. Proprioception is the sense of movement, direction, speed, location, and touch. By combining proprioception and improving the robot’s 3D perception, the researchers demonstrate that the robot can now traverse more difficult terrain, which is an advance.
Wang stated, “What’s exciting is that we have developed a single model that can handle various challenging environments.” This is because we have improved our comprehension of the three-dimensional environment, making the robot more adaptable to various situations.”
In any case, the methodology has its restrictions. Wang says that their current model doesn’t tell the robot where to go or what to do. The robot simply follows a straight line when it is deployed, and if it detects an obstacle, it walks away along a different straight line. The robot doesn’t control precisely where it goes,” he said. “We would like to include additional planning methods and complete the navigation pipeline in future work.”
Ruihan Yang from UC San Diego and Ge Yang from the Massachusetts Institute of Technology are co-authors of the paper.
More information: Ruihan Yang et al, Neural Volumetric Memory for Visual Locomotion Control (2023). rchalyang.github.io/NVM/




