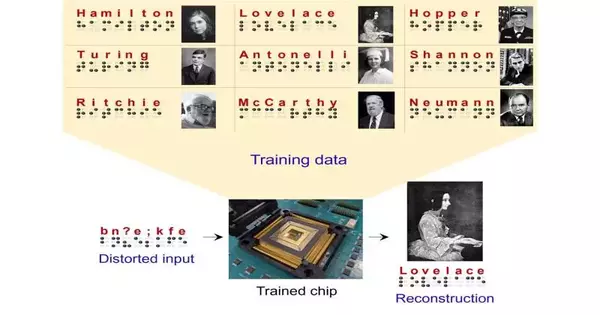
Profound learning models have shown to be exceptionally important apparatuses for making expectations and addressing true errands that include the investigation of information. Regardless of their benefits, before they are conveyed in genuine programming and gadgets, for example, mobile phones, these models require broad preparation in actual server farms, which can be both investment consuming.
Specialists at Texas A&M College, Downpour Neuromorphics, and Sandia Public Research facilities have as of late devised another framework for preparing profound learning models all the more productively and with a bigger scope. This framework, presented in a paper distributed by Nature Gadgets, depends on the utilization of new preparation calculations and memristor crossbar equipment that can complete numerous tasks on the fly.
“A great many people partner computer-based intelligence with wellbeing checking in savvy watches, face acknowledgment in PDAs, and so on; however, the majority of artificial intelligence, as far as energy spent, involves the preparation of artificial intelligence models to play out these errands,” Suhas Kumar, the senior creator of the review, told TechXplore.
“Preparing occurs in stockroom-estimated server farms, which is pricey both financially and regarding carbon footprint. Just completely prepared models are then downloaded onto our low-power gadgets.”
“Most people connect AI with health monitoring in smart watches, facial recognition in smart phones, and so on, but the vast majority of AI, in terms of energy spent, comprises the training of AI models to execute these tasks,”
Suhas Kumar, the senior author of the study,
Basically, Kumar and his partners set off to devise a methodology that could decrease the carbon impression and monetary expenses related with the preparation of simulated intelligence models, subsequently making their enormous scope execution simpler and more economical. To do this, they needed to defeat two vital limits of current artificial intelligence preparing rehearses.
The first of these difficulties is related to the utilization of wasteful equipment frameworks in light of graphics processing units (GPUs), which are not innately planned to run and prepare profound learning models. The second involves the utilization of inadequate and math-weighty programming instruments, explicitly using the supposed backpropagation calculation.
“Our goal was to utilize new equipment and new calculations,” Kumar made sense of. “We utilized our past 15 years of work on memristor-based equipment (an exceptionally equal option in contrast to GPUs) and late advances in the cerebrum like effective calculations (a non-backpropagation neighborhood learning strategy). However advances in equipment and programming existed beforehand, we co-designed them to work with one another, which empowered very productive simulated intelligence preparation.
The preparation of profound brain networks involves constantly adjusting its setup, which contains supposed “loads,” to guarantee that it can distinguish designs in information with expanding exactness. This course of transformation requires various increases, which customary computerized processors battle to perform effectively, as they should bring weight-related data from a different memory unit.
“Practically all preparation today is performed utilizing the backpropagation calculation, which utilizes huge information development and tackles numerical problems, and is hence fit for advanced processors,” Suin Yi, lead creator of the review, told TechXplore.
“As an equipment arrangement, simple memristor crossbars, which arose inside the last ten years, empower installing the synaptic load at a similar spot where the figuring happens, in this way limiting information development. Be that as it may, conventional backpropagation calculations, which are appropriate for high-accuracy computerized equipment, are not viable with memristor crossbars because of their equipment clamor, mistakes, and restricted accuracy.”
As traditional backpropagation calculations were inadequately fitted to the framework they imagined, Kumar, Yi, and their partners fostered another cooperatively advanced learning calculation that takes advantage of the equipment parallelism of memristor crossbars. This calculation, roused by the distinctions in neuronal movement seen in neuroscience studies, is open-minded to blunders and repeats the cerebrum’s capacity to advance even from scanty, ineffectively characterized, and “uproarious” data.
“Our calculation equipment framework concentrates on the distinctions in how the engineered neurons in a brain network act contrastingly under two unique circumstances: one where it is permitted to create any result in a free design, and one more where we force the result to be the objective example we need to recognize,” Yi made sense of.
“By concentrating on the distinction between the framework’s reactions, we can anticipate the loads expected to cause the framework to show up at the right response without constraining it. At the end of the day, we stay away from the intricate numerical statements backpropagation, making the interaction more commotion versatile, and empowering neighborhood preparing, which is the way the cerebrum learns new undertakings.”
The cerebrum propelled and simple equipment viable calculation created as a component of this study could consequently eventually empower the energy-productive execution of artificial intelligence in edge gadgets with little batteries, subsequently wiping out the requirement for huge cloud servers that consume tremendous sums electrical power. This could eventually assist with making the enormous scope of preparation for profound learning calculations more reasonable and maintainable.
“The calculation we use to prepare our brain network consolidates probably the best parts of profound learning and neuroscience to make a framework that can advance effectively and with low-accuracy gadgets,” Jack Kendall, another creator of the paper, told TechXplore.
“This has numerous ramifications. That’s what the first is, utilizing our methodology, man-made intelligence models that are at present excessively enormous to be sent can be made to fit in cellphones, smartwatches, and other untethered gadgets. Another is that these organizations can now learn on-the-fly, while they’re sent, for example to represent evolving conditions, or to keep client information neighborhood (trying not to send it to the cloud for preparing).”
In beginning assessments, Kumar, Yi, Kendall, and their partner Stanley Williams demonstrated the way that their methodology can decrease the power utilization related to simulated intelligence preparation by up to multiple times when contrasted with even the best GPUs available today. Later on, it could empower the exchange of enormous server farms onto clients’ very own gadgets, diminishing the carbon impression related to man-made intelligence preparation, and advancing the advancement of additional fake brain networks that help or improve on day-to-day human exercises.
“We next plan to concentrate on how these frameworks scale to a lot bigger organizations and more troublesome errands,” Kendall added. “We likewise plan to concentrate on an assortment of cerebrum propelled learning calculations for preparing profound brain organizations and figure out which of these have perform better in various organizations, and with various equipment asset imperatives. We accept this won’t just assist us with understanding how to best perform learning in asset compelled conditions, yet it might likewise assist us with understanding how organic minds can learn with such fantastic proficiency.”
More information: Su-in Yi et al, Activity-difference training of deep neural networks using memristor crossbars, Nature Electronics (2022). DOI: 10.1038/s41928-022-00869-w
Journal information: Nature Electronics




