With how much data is on the web and how it is expanding constantly, recovering significant information from a hard-to-find little item can be difficult at times. Content-based image recovery (CBIR) frameworks are fit for recovering wanted pictures in view of the client’s contribution from a broad data set.
These frameworks are utilized in online business, face recognition, clinical applications, and PC vision. There are two ways in which CBIR frameworks work: text-based and picture-based. One of the ways in which CBIR gets a lift is by utilizing profound learning (DL) calculations. DL calculations empower the utilization of multi-modular element extraction, implying that both picture and text highlights can be utilized to recover the ideal picture. Despite the fact that researchers have attempted to create multi-modular element extraction, it remains an open issue.
To this end, scientists from the Gwangju Foundation of Science and Innovation have created DenseBert4Ret, a picture recovery framework utilizing DL calculations. The review, driven by Prof. Moongu Jeon and Ph.D. understudy Zafran Khan, was distributed in Data Sciences.
“In our daily lives, we frequently search the internet for items such as clothing, study papers, news articles, and so on. When we have these thoughts, they can take the form of visuals or textual descriptions. Furthermore, we may seek to alter our visual experiences through written descriptions at times. As a result, retrieval systems should accept queries in both text and image formats.”
Prof. Jeon, explaining the team’s motivation behind the study.
“In our everyday lives, we frequently scour the web to search for things, for example, garments, research papers, news stories, and so on. At the point when these questions come into our brains, they can be as visual as the two pictures and printed depictions. Also, on occasion, we might wish to alter our visual insights through printed portrayals. “As a result, recovery frameworks should likewise acknowledge inquiries as both texts and pictures,” says Prof. Jeon, explaining the group’s motivation driving the review.
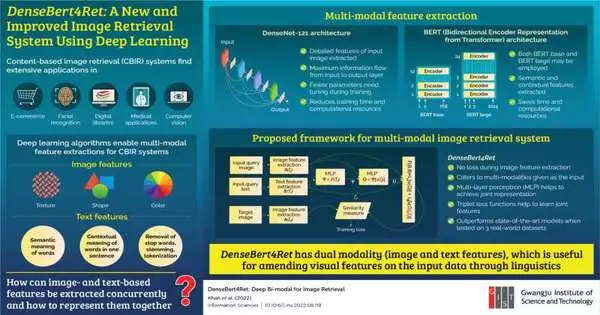
The proposed model had both pictures and text as the information inquiry. For removing the picture highlights from the information, the group utilized a profound brain network model known as DenseNet-121. This design took into account the greatest data progression from the contribution to the result layer and necessitated the tuning of a few boundaries during preparation.
DenseNet-121 was joined with the bidirectional encoder portrayal from the transformer (BERT) design for removing semantic and logical elements from the text input. The mix of these two designs decreased preparation time and computational necessities and shaped the proposed model, DenseBert4Ret.
The group then utilized Fashion200k, MIT-states, and FashionIQ, three genuine world datasets, to prepare and look at the proposed framework’s exhibition against the cutting-edge frameworks. They found that DenseBert4Ret showed no misfortune during picture inclusion and extraction and beat the cutting-edge models. The proposed model effectively cooked for multi-modalities that were given as contributions, with the multi-facet perceptron and triple misfortune capability assisting with learning the joint elements.
“Our model can be utilized anyplace where there is a web-based stock and pictures should be recovered.” “Also, the client can make changes to the inquiry picture and recover the altered picture from the stock,” closes Prof. Jeon.
More information: Zafran Khan et al, DenseBert4Ret: Deep bi-modal for image retrieval, Information Sciences (2022). DOI: 10.1016/j.ins.2022.08.119





{kind=link}