Data sets containing colossal measures of exploratory information are accessible to specialists across a wide assortment of compound disciplines. However, a group of scientists discovered that available data is useless in forecasting the outcomes of new unions utilizing artificial reasoning (AI) and AI.Their review, distributed in the journal Angewandte Chemie International Edition, recommends that this is to a great extent down to the propensity of researchers not to report bombed tests.
In spite of the fact that AI-based models have been especially fruitful in anticipating sub-atomic designs and material properties, they return rather mistaken expectations for data connected with item yields in combination, as Frank Glorius and his group of analysts at Westfälische Wilhelms-Universität Münster, Germany, have found.
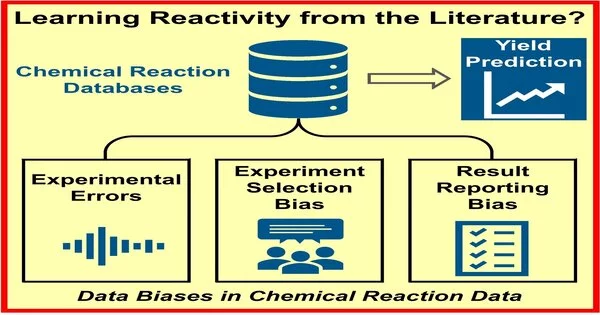
The analysts attribute this inability to the information used to prepare AI frameworks. “Strangely, the expectation of response yields (reactivity) is significantly more testing than the forecast of atomic properties.” Reactants, reagents, amounts, conditions, the exploratory execution — all decide the yield, and in this way, the issue of yield expectation turns out to be very information-serious, “makes sense of Glorius.” In this way, regardless of the gigantic measures of accessible writing and results, the scientists came to understand that the information isn’t good for exact expectations of the normal yield.
“Reaction yields (reactivity) prediction is, interestingly, significantly more difficult than molecular properties prediction. Reactants, reagents, amounts, circumstances, and experimental execution all influence yield, making yield prediction a data-intensive challenge.”
Frank Glorius
The issue isn’t simply down to an absence of tests. Conversely, the group recognized three potential foundations for one-sided information. First and foremost, the consequences of compound amalgamations might be imperfect because of a trial blunder. Also, when scientific experts are arranging their examinations, they may, either deliberately or unknowingly, present inclinations in light of individual experience and dependence on deeply grounded techniques. At long last, since only responses with a positive result are accepted to add to the advance, bombed responses are accounted for less regularly.
To figure out which of these three elements had the best impact, Glorius and the group deliberately modified the datasets for four unique, regularly utilized (and in this way, information-rich) natural responses. They misleadingly expanded trial blunders, diminished the size of the information inspection sets, or eliminated adverse outcomes from the information. Their examinations showed that the exploratory blunder had the littlest effect on the model, while the commitment made by the absence of adverse outcomes was key.
The gathering trusts that these discoveries will urge researchers to continuously report bombed tests as well as their triumphs. This would further develop information accessibility for preparing AI, at last assisting with accelerating arrangement and making trial and error more effective. That’s what Glorius adds. “AI in (sub-atomic) science will increase effectiveness decisively and fewer responses should be raced to accomplish a specific objective, for instance, an enhancement.” This will enable scientific experts and will assist them with making compound cycles more reasonable.





{kind=link}