It’s an age-old conundrum.Friday night has moved around, and you’re attempting to pick an eatery for supper. (If there are any remaining reservations because you waited as long as possible to book.)In any case, would it be a good idea for you to go to your most beloved watering hole or attempt another foundation with the expectation of finding something unrivaled? Possibly, however, that interest comes with a gamble: you investigate, and the food could be more regrettable, or you exploit and neglect to outgrow your restricted pathway.
Artificial intelligence is driven by curiosity to investigate the world, currently in an infinite number of use cases: autonomous routes, automated navigation, and improving wellbeing outcomes.Machines, at times, use “support learning” to achieve an objective, where a computer-based intelligence specialist iteratively gains from being compensated for good behavior and rebuffed for bad.
Very much like the issue faced by people when choosing a café, these specialists likewise battle with adjusting the time spent finding better activities (investigation) and the time spent making moves that prompted high prizes previously (double-dealing). An excessive amount of interest can distract the specialist from using sound judgment, and too little interest means the specialist won’t ever find great choices.
“If you grasp the exploration-exploitation trade off properly, you can learn the right decision-making principles faster—and anything less will require a lot more data, which might mean poor medical treatments, lower revenues for websites, and robots that don’t learn to do the right thing,”
Pulkit Agrawal, MIT Professor and Director of the Improbable AI Lab,
Scientists from MIT’s Unrealistic computer-based intelligence lab and Software engineering and computerized reasoning lab (CSAIL) devised a formula that overcomes the issue of man-made intelligence being “inquisitive” and becoming preoccupied by the task at hand.Their calculation consequently increases interest when it’s required and smothers it, assuming that the specialist gets sufficient oversight from the climate to know what to do.
When tested on over sixty computer games, the calculation was able to win at both hard and simple investigation tasks, whereas previous calculations could only handle a hard or simple space alone.With this strategy, computer-based intelligence specialists utilize less information for learning dynamic principles that boost motivation.
“Assuming you ace the investigation abuse compromise well, you can gain proficiency with the best dynamic principles quicker, and anything less will require a lot of information, which could mean sub-par clinical medicines, lower benefits for sites, and robots that don’t figure out how to make the best choice,” says Pulkit Agrawal, MIT Professor and Overseer of the Far-fetched man-made intelligence Lab, who regulated the examination.
Imagine a site attempting to sort out the plan or format of content to boost deals. On the off chance that one doesn’t perform investigation double-dealing well, joining the right web composition or the right site format will consume most of the day, and that implies benefit misfortune. Or on the other hand, in a medical services setting, as with Coronavirus, there might be a succession of choices that should be made to treat a patient, and to utilize dynamic calculations, they need to advance rapidly and effectively—you don’t need a poor arrangement while treating an enormous number of patients. “We trust that this work will apply to genuine issues of that nature.”
Snooping around can lead to unexpected trouble.
It’s difficult to incorporate the nuances of interest’s mental underpinnings—the hidden brain connects of challenge seeking behavior are poorly understood peculiarities.Attempts to shape our behavior have crossed investigations that have delved deeply into focusing on our motivations, hardship responsive qualities, and social and stress resistances.
With support realizing this, this cycle is somewhat “pruned” sincerely and stripped down to the frills, yet it’s very convoluted on the specialized side (who could have imagined).Essentially, the specialist should be interested when there is insufficient oversight free to evaluate various things, and if there is management, it should change and lower interest.
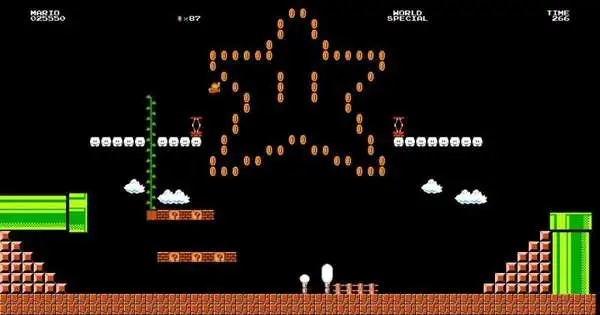
Because a large subset of gaming is little specialists going around fantastical settings looking for remunerations and performing a long series of activities to accomplish some goal, it appeared to be a legitimate testbed for the scientists’ calculation.In tests with games like Mario Kart and Montezuma’s Vengeance, they isolated expressed games into two unique containers: one where oversight was scanty, meaning the specialist had less direction, which were thought of as “hard” investigation games, and a subsequent one where management was more thick, or the “simple” investigation games.
Assume in Mario Kart that you possibly eliminate all prizes so you don’t know when an opponent kills you.You’re not given any prize when you gather a coin or hop over pipes. Finally, the specialist is informed of how well it performed.This would be one with inadequate oversight. Calculations that boost interest do well all around in this situation.
Be that as it may, presently, assume the specialist is given thick management—aa compensation for bouncing over pipes, gathering coins, and killing foes. Here, a calculation without interest performs well all around since it gets compensated all the time. All else being equal, assuming you use the calculation that also uses interest, it advances gradually.It is on the grounds that the inquisitive specialist could endeavor to run quick in various ways, dance around, and go to all aspects of the game screen—things that are fascinating—but that don’t assist the specialist with prevailing at the game. The group’s calculation, in any case, reliably performed well, regardless of what climate it was in.
Future work could include returning again to the investigation that has both gladdened and tormented clinicians for quite a long time: a fitting measurement for interest. Nobody truly knows the correct approach to characterizing interest numerically.
“Getting reliable, great execution on an original issue is incredibly difficult—sso by further developing investigation calculations, we can save your work on tuning a calculation for your concerns about revenue.” We want interest to tackle incredibly challenging issues, but on certain issues, it can hurt execution. We propose a calculation that eliminates the weight of tuning the equilibrium between investigation and double-dealing. Beforehand, it took, for example, seven days to tackle the issue effectively. With this new calculation, we can come to good outcomes in a couple of hours. says MIT CSAIL Ph.D. understudy Zhang-Wei Hong, co-lead creator alongside Eric Chen, MIT CSAIL MEng ’22, on another paper about the work.
“Inherent prizes such as interest are critical in directing specialists to discover useful assorted ways of behaving, but this should not come at the expense of getting along well at the given task.”This is a significant issue in simulated intelligence, and the paper gives a method for adjusting that tradeoff. “It would be fascinating to perceive how such techniques scale past games to certifiable automated specialists,” says Deepak Pathak, staff at Carnegie Mellon College.
“One of the best difficulties for ebbing and flowing artificial intelligence and mental science is the manner by which to adjust investigation and double-dealing—tthe quest for data versus the quest for remuneration.” “Youngsters do this consistently, however, it is testing computationally,” notes Alison Gopnik, a recognized teacher of brain science and subsidiary teacher of reasoning at UC Berkeley who was not engaged with the undertaking.
“This paper utilizes great new strategies to achieve this naturally, by planning a specialist that can efficiently adjust interest on the planet and the craving for remuneration, thus taking one more step towards making simulated intelligence specialists (nearly) as brilliant as youngsters.”
More information: Eric R Chen, Zhang-Wei Hong, Joni Pajarinen, Pulkit Agrawal, Redeeming intrinsic rewards via constrained policy optimization. openreview.net/forum?id=36Yz37cEN_Q





{kind=link}