Digital aggressors are concocting increasingly modern strategies to take clients’ delicate data, encode records to get a payment, or harm PC frameworks. Therefore, PC researchers have been attempting to make more powerful strategies to recognize and forestall digital assaults.
Some of the malware locators created lately depend on AI calculations prepared to consequently perceive the examples or marks related to explicit digital assaults. While some of these calculations produced impressive results, they are normally vulnerable to malicious attacks.
Ill-disposed assaults happen when a malevolent client bothers or alters information in unobtrusive ways to guarantee that it is misclassified by an AI calculation. Because of these unpretentious irritations, the calculation could arrange malware as though it were protected and customary programming.
Scientists at the School of Designing in Pune, India, have as of late completed a review exploring the weakness of a profound learning-based malware locator to ill-disposed assaults. Their paper, pre-distributed on arXiv, explicitly centers around a locator in light of transformers, a class of profound learning models that can weigh various pieces of information in an unexpected way.
“Many of these models have been discovered to be vulnerable to adversarial assaults, which work by creating purposely prepared inputs that force these models to misclassify. Our research attempts to investigate weaknesses in today’s cutting-edge malware detectors to adversarial assaults.”
Yash Jakhotiya, Heramb Patil, and Jugal Rawlani
In their paper, Yash Jakhotiya, Heramb Patil, and Jugal Rawlani wrote that “many AI-based models have been proposed to productively recognize a wide assortment of malware.”
“A large number of these models are viewed as powerless to ill-disposed assaults—assaults that work by creating deliberately planned inputs that can drive these models to misclassify. Our work means investigating weaknesses in the present status of the craft malware finders to antagonistic assaults. “
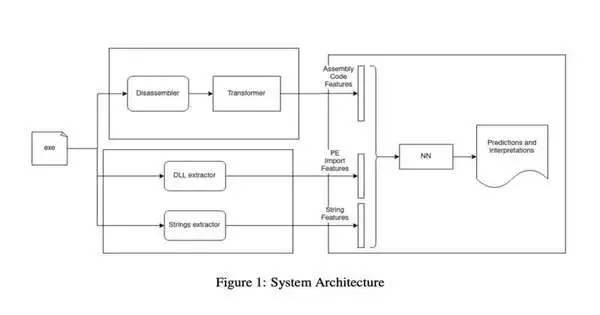
To survey the weakness of profound learning-based malware identifiers to ill-disposed assaults, Jakhotiya, Patil, and Rawlani fostered their own malware identification framework. This framework has three key parts: a get-together module, a static element module, and a brain network module.
The gathering module is responsible for ascertaining low-level computing constructs that are subsequently used to arrange information. Utilizing similar information taken care of to the gathering module, the static component module produces two arrangements of vectors that will likewise be utilized to characterize information.
The brain network model purposes the highlights and vectors delivered by the two models to characterize documents and programming. At last, it will probably decide if the records and programming it investigates are harmless or pernicious.
The scientists tried their transformer-based malware identifier in a progression of tests, where they evaluated how its presentation was impacted by ill-disposed assaults. They observed that it was inclined to misclassify information very nearly 1 out of every 10 times.
“We train a Transformers-based malware locator, complete ill-advised assaults, resulting in a misclassification rate of 23.9%, and propose safeguards that cut this misclassification rate in half,” Jakhotiya, Patil, and Rawlani wrote in their paper.
The new discoveries accumulated by this group of analysts feature the weakness of current transformer-based malware finders to antagonistic assaults. In view of their perceptions, Jakhotiya, Patil, and Rawlani consequently propose a progression of safeguard methodologies that could assist in expanding the strength of transformers prepared to identify malware against ill-disposed assaults.
These procedures remember preparing the calculations for antagonistic examples, concealing the model’s slope, diminishing the quantity of elements that the calculations check out, and obstructing the alleged adaptability of brain structures. Later on, these procedures and the general discoveries distributed in the new paper could contribute to the advancement of more compelling and dependable learning-based malware finders.
More information: Yash Jakhotiya, Heramb Patil, Jugal Rawlani, Adversarial attacks on transformers-based malware detectors. arXiv:2210.00008v1 [cs.CR], arxiv.org/abs/2210.00008




