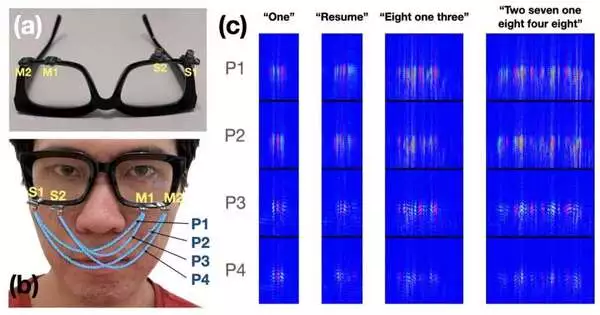
Researchers at Cornell University have created a silent-speech recognition interface that employs artificial intelligence and acoustic sensing to continuously recognize up to 31 unvocalized commands based on lip and mouth movements.
Just a few minutes of user training data are needed for the wearable, low-power EchoSpeech interface before it is ready to run on a smartphone and recognize commands.
The lead author of “EchoSpeech: Continuous Silent Speech Recognition on Minimally Obtrusive Eyewear Powered by Acoustic Sensing,” which will be presented this month at the Association for Computing Machinery Conference on Human Factors in Computing Systems (CHI) in Hamburg, Germany, is doctoral information science student Ruidong Zhang.
“We’re very excited about this system because it significantly advances the field in terms of performance and privacy.” It’s compact, low-power, and sensitive to privacy, which are all crucial characteristics for implementing new, wearable technology in the real world.”
Cheng Zhang, assistant professor of information science.
This silent speech technology could be a great input for a voice synthesizer for people who are unable to vocalize sound. If the technology is developed further, Zhang said, it might be able to give patients their voices back.
In its current state, EchoSpeech can be used to talk to people on the phone in environments where speech is difficult or inappropriate, such as a busy restaurant or a quiet library. When used with design software like CAD, the silent speech interface can be used in place of a keyboard and mouse. It can also be used in conjunction with a stylus.
The EchoSpeech glasses transform into a wearable AI-powered sonar system, sending and receiving soundwaves across the face and sensing mouth movements, when equipped with a pair of microphones and speakers no larger than pencil erasers. Then, with a 95 percent accuracy rate, a deep learning algorithm analyzes these echo profiles in real time.
The Smart Computer Interfaces for Future Interactions (SciFi) Lab at Cornell University is directed by assistant professor of information science Cheng Zhang, who stated that “we are moving sonar onto the body.”
Because it significantly advances the field in terms of performance and privacy, he added, “We’re very excited about this system. It has several key characteristics that are necessary for deploying new wearable technologies in the real world, including being compact, low-power, and privacy-sensitive.
According to Cheng Zhang, the majority of silent-speech recognition technology is constrained to a small number of predetermined commands and requires the user to stand in front of or wear a camera, neither of which is feasible or practical. He added that there are significant privacy issues with wearable cameras for both the user and those with whom the user interacts.
Wearable video cameras are not necessary thanks to acoustic sensing technology like EchoSpeech. And because audio data is much smaller than image or video data, it can be transmitted via Bluetooth in real time to a smartphone and requires less processing bandwidth, according to François Guimbretière, professor of information science.
Privacy-sensitive data never leaves your control because it is processed locally on your smartphone rather than being uploaded to the cloud, he added. “.
More information: Conference: chi2023.acm.org/
Research: ruidongzhang.com/files/papers/ … _authors_version.pdf




